
State of the Themes January 2024
Core Portfolio and Thematic Basket Developments & New AI + GLP-1 Plays

The State of the Themes
Our thematic equity baskets have done pretty well, and I’m happy that’s the case. But, if I’m being honest, there’s nothing in trading that makes me more paranoid than being right.
Being wrong grants you the optionality of recognizing you’re wrong and taking action to address your wrongness, while being right gives you one solitary correct course of action with a million ways to mess it up.
In my article The Art of Being Wrong, I wrote about a trader who I look up to - someone who’s humility and grace upon realizing they were on the wrong side of a trade made them that much more effective at generating PnL. I’ll share another piece of wisdom I learned from him:
”When you’ve found a good thing, know when to leave it the f*ck alone”
Sometimes, the more you think about something, the more opportunities you give yourself to make really dumb decisions that are extraordinarily well thought out.
Right now, we’ve been allocated to these themes (AI, GLP-1s, Fiscal) for the better part of a year in some cases. We’ve left it alone, and it’s worked. And now we are gonna mess with it…because I think it’s finally time.
Plenty of you have asked me when I’m going to update the thematic baskets. Let me tell you, it’s quite deliberate that I put on these trades and then try to tinker with them as little as possible. “A wizard arrives precisely when he means to…” type thing. I mean, really…
Did you want to be updated as to every ill-informed tabloid article or big bank sell side research piece on why GLP-1s will <make you suicidal/make your teeth fall out/make planes use less jet fuel>?
Did you really want an AI update on “the implications of Sam Altman’s coup”?
If you answered yes…you’re wrong.
Because all of those little fluctuations in narrative are similar to an upward trending chart. They go up, they go down, the only thing that matters when you’re long is that - over the long term - the peaks and troughs are successively higher. There’s risk now, though, that those troughs make some lower lows. Thus, we adjust.
Synthesizing new information and discerning what is signal vs. noise is top priority when you believe you’ve found a long term theme to stick to. Highlighting the noise is the opposite of the purpose of this newsletter.
Keeping with it…
Decisions should be made at inflection points, when things get too disconnected from reality. We are attempting to predict the future here, there are going to be things we get right that have little upside left and things we get wrong that need to be adjusted - as well as new winners and losers that emerge.
It doesn’t just have to do with bubble-like analyst estimates (which are currently, deeply reflexive as upgrades on higher estimates validate higher price targets which validate upgrades…). Our decision to adjust this basket comes from the fact that the theme itself is adjusting, it’s new technology after all.
Themes evolve, and exposures that made sense for a theme a year ago may not make sense now. In-depth updates to our thematic view like these will continue to be rarely released only when there has been sufficient change in the intra-thematic environment to warrant messing with it, but that’s the case for both AI & GLP-1s.
In the 2024 outlook, I updated some of the developments and interesting headlines across our themes (which you can view here) with the exception of US Fiscal Policy1. I have waited to put out a full update with new additions and deletions until I was fully comfortable I wasn’t just tinkering unnecessarily.
It is time to analyze who’s likely to continue winning. Our thesis has been tested by the market and proven its mettle, our response is to carefully refine our initial assumptions.
Artificial Intelligence & Machine Learning: The Next Phase
My take overall is that we are deeply established in the AI bubble now, in the sense that it is here and AI will continue to proliferate. As far as timing, using the trend of mobile phones, personal computing or the internet…we’re still pretty early in the real world implications.
The AI adopters have yet to really make an impact, which is to be expected as phase one plays out in its entirety. Where we are in terms of reality vs. estimates is another thing entirely.
When we first began delving into AI as a promising thematic investment, . The first basket “AI Beneficiaries” overweighted the beneficiaries of the first phase - the phase in which providers of the computing power would enable the paradigm of AI to be adopted, democratized and ultimately proliferate throughout the economy.
This basket was a qualified success.
AI was, indeed, a thing. It’s very existence resulted in estimates for the companies that provided the infrastructure being far too low and sparked a virtuous cycle of capex investment and surging stock prices. You can revisit it here, the three phases are just as important now as they were when it was written:

Let’s discuss what to do now that the picks and shovels are trading at historically high multiples and beginning to price in some silliness.
Analyst estimates on names like NVDA and SMCI have entered a virtuous cycle wherein the stock price increases seem to validate the price targets.
Up until now, estimates have remained within the realm of the achievable. That’s about to change.
Paid subscribers, as always, have access to all position changes as well as the overall Core Portfolio holdings & weights (which is updated twice monthly and can be viewed at any time under the “Citrindex” tab on the homepage). This article covers:
positioning for new and expected developments that may change the investment landscape for Artificial Intelligence & Machine Learning
my view on risks to expected returns of the AI basket now that we’re in “the AI bubble”
an overview of how LLMs (and eventually GPUs) become commoditized
some potential long/short plays in both AI & GLP-1 thematics
[Paid Content Below: Unlocked for Free Subscribers March 14th 2024]
Picking Shovels
The thesis to significantly overweight out Phase 1 beneficiaries (later called “picks and shovels” by the sell-side) was correct. Now, it’s consensus.
It is important to recognize when and how you’ve won on a trade, not for bragging rights but to ensure you don’t turn a winner into a loser.
Most of the performance has been driven by increased earnings expectations rather than multiple expansion, although there has been some multiple expansion:


This is a precarious yet familiar position for a heavily narrative driven investor such as myself. Thematic expectations are always at risk for being exaggerated because of how catchy the story is.
Now, don’t get me wrong, there is plenty of room for EPS expansion.
There’s also some very lofty expectations being priced in, and with a rapidly advancing technology the chance that some of these names are blindsided by novel threats to dominance or new entrants is high.
Realize that we began getting long this basket with an average P/E between 18x and 20x, well below the historical mean. The P/E is now 35x. The highest it’s been on this basket since the peak of the ZIRP-Covid Tech Bubble. “AI will change the world” and “It’s time to take some profits on AI” are not mutually exclusive beliefs. There is no cognitive dissonance there.
And it’s not just about whether to take some chips off the table or not - it’s about realizing that the table stakes (and perhaps even the game we’re playing) has changed, as technology is wont to do.
It’s important to note that when I was writing the first AI article much of what I was writing about was speculation on the future. I was filled with bullishness and pure, unadulterated optimism.
Why? Because the forward expected returns on the names in our basket - which had been abused by the cyclical downturn and traded cheap as hell - were high regardless of if I was proven a AI prophet or an AI Idiot (AIdiot?). While we are still always speculating, we have a bit more data now.
What does that data look like?
Pretty good.



Even if the data was a massive neon sign that said “EVERYTHING IS FINE OVER HERE”, I’d still be worried if that data caused my longs to be overvalued by a couple orders of magnitude.
Remember:
BULL MARKETS CLIMB THE WALL OF WORRY
BEAR MARKETS SLIDE DOWN A RIVER OF HOPE
This is one of the most famous Wall Street truisms. I am not sure who originally said this, but it rings true through the decades. What does it mean? Simply put, it means every bull market in stocks is doubted by a cadre of naysayers. There is always a vocal group of skeptics who point out a myriad of very rational and quite possible potential events which could derail the market’s ascent. In this sense, during a bull market, stocks are said to “climb a wall of worry”.
Bull markets end when the last holdout doubters finally throw in the towel, when FOMO—Fear Of Missing Out—gives in to greed and the last dollar is invested in the market. The constant drip, drip, drip of daily negative news is another brick in this massive wall of worry, which the optimists of the world try to overcome. This is an oversimplification of a very complicated process, but it holds true.
The supply of naysayers has dried up considerably in the realm of AI, but at the same time real earnings growth has occurred. NVDA’s EPS this quarter is expected to be more than seven times higher than the same quarter last year. Our job is finding out whether (and where) we’re priced to perfection.
Global AI Beneficiaries Basket (AI Longs)
Just to review, in case you’re a newer subscriber and haven’t looked through the thematic equity archive, our May 30th 2023 thesis on Artificial Intelligence & Machine Learning beneficiaries was a collection of ~128 names
It was expanded on a bit in my year end article but I - more so than anyone else, what with being the author - understand how excruciatingly long my “24 Trades for 2024” article was. I know most of you just skimmed it, and that’s fine - it was meant to be skimmed!
In this article, I’ll be revisiting and expanding upon a few of the ideas I touched on in there. So I’m going to link the part relevant to the below if you’d like to read it to get up to speed on the Phase 1 environment and the developments in I expect in Phase 2/3.
Quick Recap:
Phase 1 focused on the data center hyperscaling and infrastructure needed to enable AI/ML, including semiconductors, connectivity, data centers, etc. It goes into detail on specific companies within these areas poised to benefit. Once the phase one build is over, I find it personally unlikely that inference will carry the semi boom in the same way it has thus far, we will need bigger and better models - and eventually the we’ll plateau. But I think that will take at least a few years & the build will take longer than just 2024/2025, as parallel computing becomes even more advanced.
Phase 2 discussed the democratization and proliferation of AI/ML through frameworks, cloud platforms, business applications, etc. It talks about companies providing the tools, platforms and services to implement AI across industries.
Phase 3 dealt with deeper integration of AI/ML and potential future scenarios like hyper-personalization, increased automation, and virtual/augmented reality. It highlights some companies likely to play major roles which were viewed as moonshots.
Just because the thesis was correct, however, does not mean that holding on was easy - there has been wild volatility. By the end of October, our AI basket had gone from being up 25% since publication at the peak to being up just 0.31%. But I didn’t panic, the market had yet to accurately reflect the potential of our Phase 1 beneficiaries. I simply said to buy the dip, and now it’s up more than 40%.
Why has it been 9 whole months since I deemed it useful to do a deep dive on updating our thematic priors in AI? I refrained for so long not because my conviction wavered, but because I didn’t want to give my readers a reason to waver in theirs. I am telling you now, reader, it’s time to get a little paranoid.
Let’s talk about some of the sub-themes likely to continue exerting influence on the market as AI continues.
HYPE CYCLE CARTOGRAPHY
Let’s summarize where we’ve been, where we’re at, and where we’re going. First, let’s map out the hype cycle in general, how it’s played out historically, and then as it relates to AI/ML both in reality and in markets.
In terms of AI expectations…
uhhhh, the curve has steepened 😂.
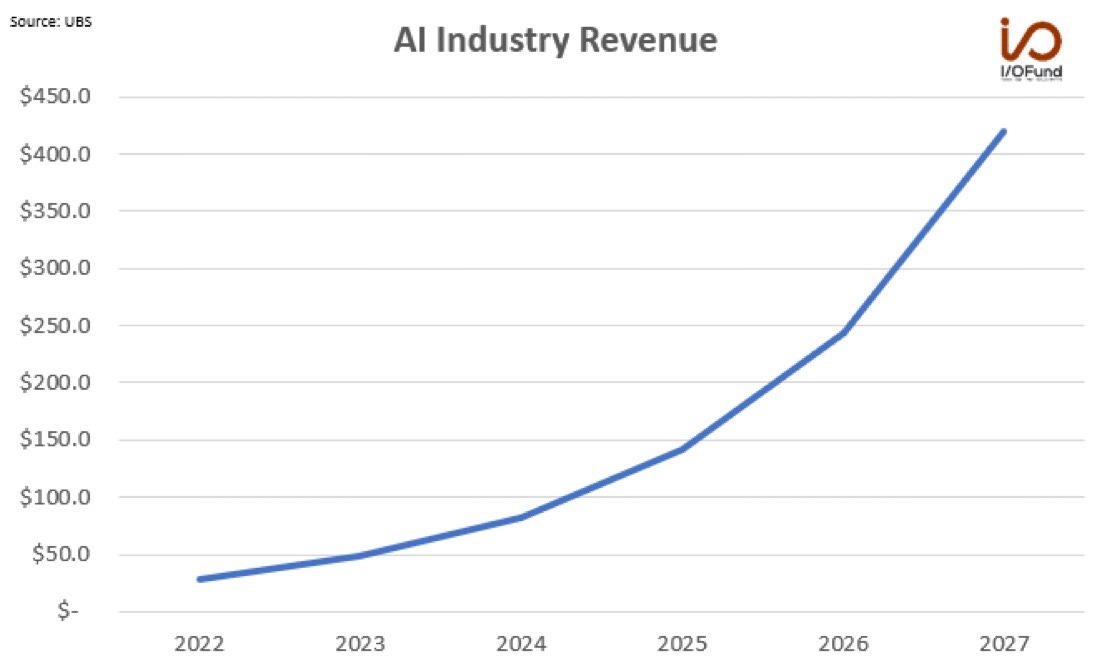
UBS is predicting AI industry revenue to grow to $420 billion by 2027, a 40% increase from its prior view of $300 billion.
This would represent a 72% CAGR from $28 billion in 2022.
That’s nearly as big as the entire semiconductor industry this year.
That reflects a true believer degree of optimism, there is no skepticism here. However, it is still kind of conservative by bubble standards. These are somewhat achievable goals, perhaps in some specific cases goals that can be exceeded.
But that doesn’t help us necessarily.
It’s not going to be as easy as “NVDA GPU revenue is the majority of AI revenue forever”. The bulk of this 15X’d 2027 revenue may end up coming from some company that’s currently private (or maybe doesn’t even currently exist!) and ends up making its money, in part, because compute has gotten extraordinarily cheap by 2027.
In that scenario, you can be forecasting 500 billion of AI revenue in 2027 and be proven exactly right in 3 years. But, let’s say your expression of that was long NVDA and by the time you’re proven right maybe ASICS have emerged, GPU competition has gotten cutthroat as challengers have scaled, inference has gotten more important than training, parallel computing has gotten commoditized and - in light of all that - NVDA’s 2027 gross margin is going to be 10% and, actually, their market share has gone down. You were right on the broad picture and dead wrong on the second order assumptions because of risks to your priors.
Broadly, however, current 2027e numbers are likely at the high end of what is realized and most are unlikely to have significant upside surprises, so if you’ve been playing the fundamental AI story, I’d say that you should be aware the time to sell your fundamental “picks and shovels” names is near and/or here.
However, hype cycles don’t play by the rules of reality and fundamentals become reflexive. Perceptions change economic reality which changes perception. Breaking out of this virtuous cycle to enter a vicious cycle takes a catalyst that’s more significant than merely “these stocks have likely surpassed their fair value estimate”.
If part of why you’re in AI/ML is to position properly for the hype cycle, there are a few considerations. First, if we actually go into a bonafide AI-driven bubble reminiscent of the late 90s…it can get so much crazier. Orders of magnitude sillier. Let’s take a historical example.
Historical Precedents: The Telecom Bubble
I’ve spent some time looking at the early 2000s telecom (and earlier dot com) bubble as a parallel. It was widely correct in terms of the impact of cell phones and the internet on reality, but that didn’t mean it didn’t go parabolically up and then down.
Analysts were modeling every humanon earth with 2 cell phones.
“Well, Citrini” you might say, “that’s not so far off from reality today!!”
Okay, but the thing is, it wasn’t the prediction of the proliferation of the technology they got wrong - but that also wasn’t the prediction that actually mattered. After all, it’s not the tech becoming widespread that is important, it’s the degree to which the tech becoming widespread results in growth for revenue and profits. You see, the fatal mistake in technologically driven bubble estimates is that analysts do two things wrong when they’re at the peak of inflated expectations:
they extrapolate out from early winners that are most vulnerable to new developments (think AOL)
they forget to discount for technological innovation driving price deflation
Here’s the answer to why those analysts got the stocks wrong but the technological paradigm correct: dot-com bubble estimates reflected a world where consumers had gone from spending fifteen percent of their disposable income on cell phone service & internet access to SPENDING SIXTY PERCENT OF THEIR DISPOSABLE INCOME ON INTERNET ACCESS.
They were correct in the sense that everyone would own a cellphone. They were correct in the sense that internet/mobile service would become a higher percent of disposable income. They were off by multiple orders of magnitude in how high that percent would be.
Today, the average American household spends just 2.9% of their disposable income per annum on internet and cell phone service.
Do you see what I’m getting at here? It’s completely possible to be dead right about a technology, and then your thesis is proven correct by the market as everyone else realizes it is the future, and then you get smoked because the latecomers make expectations clinically insane to justify their FOMO buying.

Our first goal, always, is to get in directly after the innovation trigger. That’s before the consensus view sees the paradigm shift and remains overwhelmingly skeptical. Our hope is that we ride the realization, and that process during which reflexivity takes hold in both prices and estimates and makes us loads of money.
Once that’s well underway, there’s a point reached where you’ve gone from earnings expectations having nothing to do with <insert theme> (internet, smartphones, AI in our case right now, whatever the next thing is) to having everything to do with it. And every sell side shop’s favorite long is getting modeled as a share winner. And their earnings reports move the entire market. Now, sell side models collectively somehow project 5 separate companies to each have 70% market share.
PEAK. OF. INFLATED. EXPECTATIONS.
Learn it. Memorize it. Recognize it.
Now you have got estimates that are baked in, they’re consensus, they’re the bar that has to be met…and, in all likelihood, they are impossible to beat. This is a process that is bolstered early in the hype cycle by skeptics who are inherently negative on the potential of the theme resulting in estimates chronically being too low, thus everyone gets used to the winners consistently beating estimates by a wide margin and it seems to be unthinkable that they would fail to meet and exceed expectations. The skeptics capitulate, the true believers double down, the estimates untether from reality. And then companies begin missing on revs, EPS and guidance by wide margins.
Our second goal is to get out at the peak of inflated expectations while prices reflect a scenario that is impossible to accomplish, well before the market realizes that’s the case.
And you know what, while we’re not spending 60% of disposable income on internet service, we ARE spending nearly 50% of our disposable income online. If you had landed on that conclusion about the future of commerce being e-commerce via some second order thinking that looked beyond the obvious first order “internet & mobile is going to grow so buy internet providers” insight, that was pretty much enough to kill it for the next two decades. Right now, the GPUs are the obvious result of first order thinking. That’s perfect for early cycle - you don’t want to overcomplicate things and risk the market not joining you - it works great, until it doesn’t. We want to ride Phase 1 and obvious Phase 2 names to the top, wait to short them when the market has gotten ridiculous and get confirmation on that by some weak earnings followed by weaker price action and then use our second-order thinking to pick some of the Phase 3 winners we can grab cheap at the trough of disillusionment.
Sometimes, but not always, the peak of inflated expectations is not the actual top. Sometimes the market continues on multiple expansion as earnings misses are explained away and companies are incentivized to provide ridiculous guidance to keep their share price afloat. Most of the time, however, there’s a pretty close relationship.
AI/ML Phase One: Situation Report
It is the base case that AI will be the size of the entire current global semiconductors market and 4x the annual capex of all the hyperscalers. This means there is still much room for estimates to get wildly out of hand in a bubble-like sequence, but that they’ve already entered rarified air. The downside risks become more pronounced any higher we go from here without significant earnings beats and raises. It is no longer enough for companies to report in-line right now.
If we build it…
One question facing the market is hyperscaler decision making versus reality. As long as MSFT, AMZN, and GOOG see competitive threats in artificial intelligence that are not kept out by the barrier for entry, they will keep building to ensure they aren’t disrupted.
“If you build it, they will come" is a strategy that takes an approach with significant and potentially terrifying implications for capex spending and consumption over the next few years.
To go back to our earlier historical parallel, the telecom bubble progressed while companies dropped $150-200 billion per year in capex from 1995-2002. Why? Because the infrastructure was deemed necessary. For nearly the next decade, however, the fears of capacity constraints proved baseless. Only about 10% of the capacity ended up being used during the first 5-10 years of its existence. This massive glut resulted in a large deflationary impulse that is a common story in new technology. Until telecom truly ramped in the late 2000s, this capacity represented a monument to irrational near term expectations.
Do we have irrational expectations right now on names like SMCI?
To be quite honest, probably.
What about on NVDA?
Eventually NVDA will be disrupted by another player that will similarly build out more capacity than necessary. NVDA itself has been dealing with their capacity constraints as huge strides have been made in advanced packaging (CoWoS - a bottleneck we discussed in our original AI primer). The lead time for a H100 has gone down from 9-12 months to 3-6 months. However, as long as NVDA has the competitive advantage, they don’t care much about causing a glut of supply (and the likelihood of one is much lower).
They’ll want to take as much advantage as possible of the fact that no viable alternatives in ASICs or GPUs for training currently exists. This can mean that they’ll continue to beat and raise for the next couple quarters, but will eventually cause the circumstances that result in a race to the bottom.

NVDA is well positioned to take advantage of most scenarios over the next 12 months that don’t include a competitor with massive capacity and scale releasing an Enterprise/Hyperscaler-level ASIC for both training and inference.
An unwind of the AI TRADE is probably unlikely over the next 12 months, everything we’ve seen suggests that capability scales with compute, while I’m sure eventually we will hit a ceiling I don’t believe it’s close.
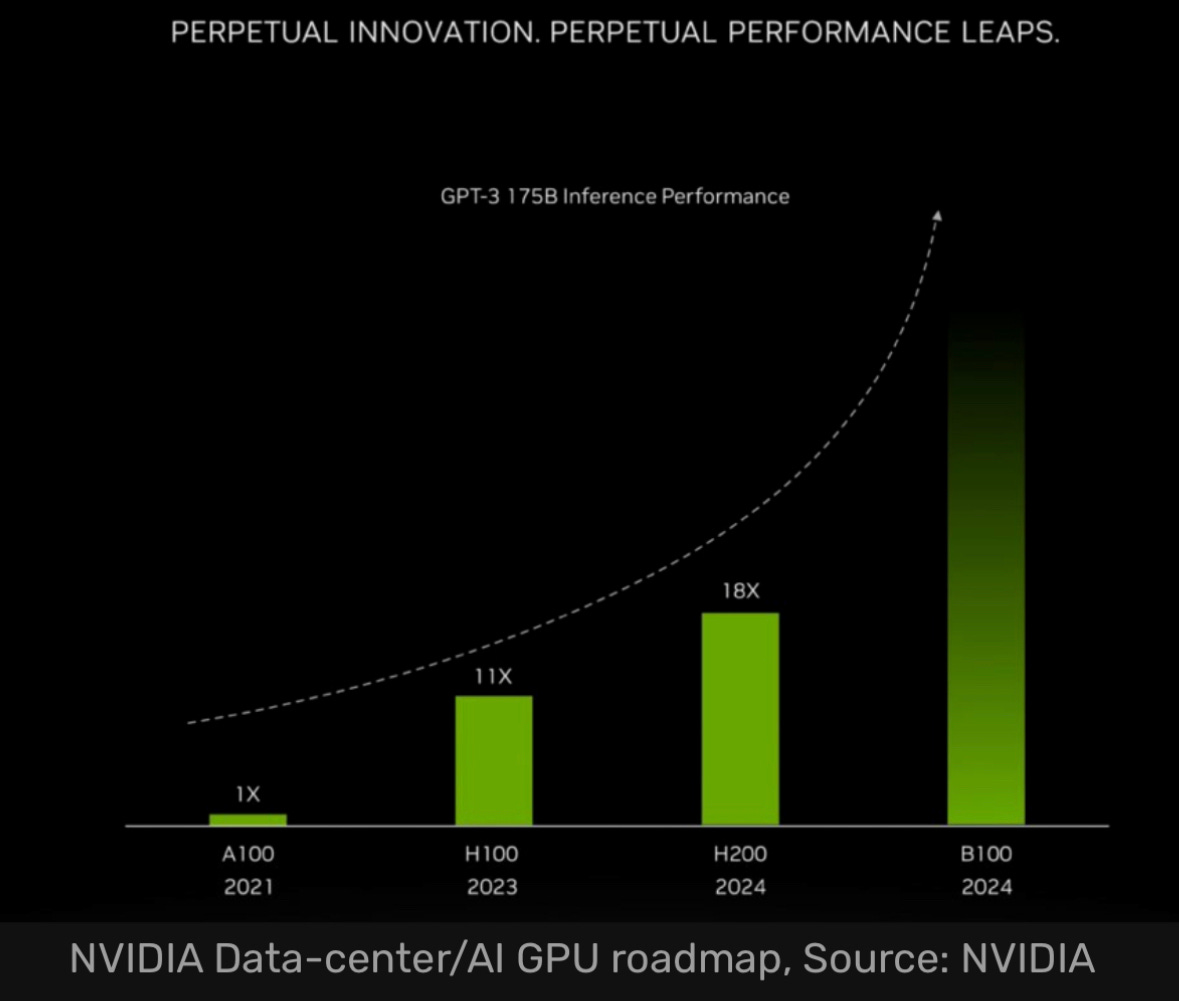
That’s separate from the efficiency of models resulting in the commoditization of LLMs, which may well accelerate - we’ll cover later.
Adding Networking and Memory to the AI Basket
We originally were very underweight memory and networking due to the bleak outlook for telecom as well as the more obvious layup in datacenter / GPU names back when they were still quite cheap. However, I believe it is time to begin adding some of them in.
Why is that? Look at the topic everyone is talking about in AI/ML - Sam Altman’s chip startup. There has been much talk about the threat to NVDA’s dominance by AMD and custom silicon (like Sam Altman is pursuing). This is part of the reason why we believe the easiest way to make money from here in Phase 1 AI will be in networking and memory.
Between the proliferation of AI/ML in sensors, Agentic AI (which inherently uses a LOT of memory), robots, drugGPT, MR, gaming, even use cases we are not yet aware of…all of it will take networking and memory. This is regardless of whether NVDA retains its top-dog status or is threatened by custom silicon like Sam Altman wishes to create - custom chip numbers are still small, but if they were to ramp up…
...just look at what AMD MRVL & AVGO and related stocks did on a few months of upward revisions of few 100K units.
EVERY custom ASIC or SMCI server (for training, as inference can use SRAM) using MI300X needs even more HBM.
Even basic AI edge needs 4GB more DDR5 and that's just the start.
Even if Nvidia were to see rising competition from custom AI chips, the growth in edge AI, robots, metaverse and other emerging use cases will drive enormous demand for complementary technologies like networking, memory and storage. Some key implications:
Connectivity providers with strengths in areas like 400G optics/SmartNICs (Marvell), 5G (Qualcomm) and hyperscale switches (Arista) enable data movement for distributed training and localized inference. I still believe it’s important to be long potential moonshot names like Credo Technologies in this space as well. More endpoints magnify need for low-latency data fabrics. Coherent expects AI Datacom revenue to be “substantial” in FY24 and expects it to continue to grow into 2H of CY24 as the 800G switch ramps.
We add CIEN, COHR and our existing overweight on MRVL to the AI basket.
Memory technologies from High-Bandwith Memory (HBM, Micron/SK Hynix) to storage-class memory and persistent memory allow much larger models and datasets and actually useful AI. Memory is a key constraint today for actual Agentic AI and On-Device Inference. Considering the environment, it’s not impossible that we see Micron and/or SK Hynix double within the next two years. High-bandwidth memory (HBM) and advanced interfaces continue to play a crucial role in maximizing AI accelerator performance, mitigating any model size limits. HBM enablers and inspection tools (like Hanmi Semiconductor and Onto) should also continue to do well.
We overweight SK Hynix & Micron in the AI Basket.
So while AI compute engender battles may shift amongst GPUs, TPUs and new ASICs, innovation across semiconductors and infrastructure remains imperative to utilize and scale AI. It lifts many boats by expanding this $300B+ market.
I do not yet think we are truly in an “AI bubble”, but if that is truly what is in our future it’s important to realize that sell-side estimates can get truly silly. Every company covered becomes a share winner, and when you are modeling 60% share for 5 companies, bottom-up estimates get insane. This is what provides seemingly fundamental justification for the next leg up. I believe we will be best served by continuing to focus on the companies who will see durable improvement in their businesses due to AI/ML, and let the market decide how hyped up to get.
Commercializing AI
Edge AI
While we are discussing commercializing AI, it’s important to understand what “Edge AI” means. Edge AI refers to deploying AI capabilities on local devices, rather than in a centralized data center or cloud. This allows for benefits like lower latency, reduced connectivity dependencies, better data privacy and scaling cost-effectively.
Commercializing Edge AI will benefit companies making specialized AI accelerator chips designed for on-device inferencing rather than training the most. Examples include Nvidia's Jetson modules, Google's Edge TPU, and Qualcomm's Snapdragon processors.
Leveraging edge capabilities allows for use cases like real-time video analytics, AR/VR, autonomous machines, IoT and predictive maintenance and reduces the need for constant cloud connectivity.
Language models with over 100 billion parameters are used in large data centers for complex tasks like autonomous driving or large-scale drug development. In contrast, edge devices like smartphones and PCs require simpler functionalities, negating the need for such large-scale models. This is why models like Meta's LLaMA, with around 7 billion parameters, are sufficient for On-Device AI. As these models become more efficient, the proliferation of Edge AI will increase.
While Phase 2/3 beneficiaries may still be a couple years from being the primary beneficiaries of AI as a trend, it is important to watch the subsectors that emerge in Phase 1 as new Phase 2 solutions become mainstream (similar to the progression of internet → ecommerce or computing → cloud).
Because Qualcomm and Mediatek will likely be the “picks and shovels” of Edge AI and it seems that the handset cycle has firmly bottomed, we will be adding it to the Phase 1 of the AI basket where previously it was absent.

The Commodification of Large Language Models:
The commodification of large language models (LLMs) like ChatGPT refers to these AI technologies becoming widely accessible as low-cost commodities rather than proprietary, differentiated offerings. This poses a threat to companies attempting to create premium LLM-based products and services. Lucky for us, many of the foundational AI model companies are still private, so we don’t have to worry too much about that when focused on public markets. However, commoditized LLMs could significantly benefit other segments:
Hardware Providers: As more businesses seek to leverage commoditized conversational AI, demand grows for the infrastructure required to run language models - specialized AI accelerators, high memory/bandwidth servers, data center capacity. This favours providers like Nvidia, Arista Networks, Marvell, Hanmi Semiconductor, Micron, SK Hynix and Credo for optimized hardware.
Integrators & Consultancies: With easy availability of conversational interfaces and text/speech recognition, system integrators like Accenture, Genpact and IT consultancies would see rising demand to build customized natural language solutions integrated across organizations' stacks. Expertise in optimizing and applying commoditized LLMs becomes key.
Vertical AI Specialists: Sector-specific companies can utilize their domain knowledge and extensive datasets to fine-tune and customize commodity LLMs for unique industry applications - drug discovery in pharma using chemical data (like Recursion or AbSci), fraud prediction and credit scoring (Experian). Specialization preserves value-add.
Platforms & Data Providers: Providers of data/model governance, version control and collaboration tooling for commoditized AI would gain traction - enabling organizations to manage myriad LLMs. META and AMZN are good examples. Similarly, supply of high-quality training data for diverse use cases persists despite model commodification.
Integration to Workflows = Integration to Industry-Standard Applications that Dominate those Workflows
I believe the trend is away from a general focus on conversational AI chatbots that aim to be capable of anything and everything. While the initial hype cycle with ChatGPT centered on the promise of a human-like assistant, the more practical path ahead involves tighter integration of AI into specific workflows and industry applications.
In other words, datasets are still king for the AI adopters.
As frameworks like Hugging Face Diffusers and Anthropic's Constitutional AI become standardized ways to implement language model architectures, the actual model design becomes less differentiated. What grows more important is the data that trains and tunes these models for particular use cases. Rich vertical data combined with customization will be vital.
This means seamless embedding within existing platforms and software that dominates in certain sectors is essential to maximize value. Rather than rip and replace, AI integration as a capability layer on top of apps or workflows employees already utilize drives adoption. Process refinement occurs before process transformation can.
Some types of applications and sectors likely more prone to this trend include sales tools enhanced by predictive analytics, engineering programs augmented with computer vision inspection, healthcare mixed with precision diagnosis apps, manufacturing paired with inventory analytics and so on.
Providers catering to these markets who take an open, interoperable approach to augment rather than supplant incumbent systems are best positioned to ride this wave. As barriers to basic AI deployment fall, the focus turns to domain expertise and change management required to extract benefits rather than novel model designs that grab headlines. Delivering ROI matters most.
Finding additional areas where dominant software/workflows intersect with AI applicability will be key, whether in sales enablement, engineering design, manufacturing quality etc. It unlocks major long vs. short potential.
Delving Deeper on Long/Short AI
The funny thing is the more I researched long/short pairs on this theme, the more I ran into the fact that the companies I’d want to be long have already been acquired by names in the AI beneficiaries basket. All the companies that we are short in software will eventually get decimated by AI advancements. However…
I do a lot of my equity research via reading online, and then most of the time I’m reading about companies that are public. Imagine my surprise when I figured I’d found a perfect one, long Cerner (among the largest electronic health records platforms with huge provider base) - which I intended to pair with a short on a company that has less proprietary health data like DOCU or GDRX - only to discover it was acquired by Oracle in 2022.
Then it happened again, I found a great long for a similar play - Nuance Communications. Guess what? Acquired by Microsoft in 2022. At this point you kind of have to wonder if all the obvious longs in this area have not already been gobbled up by the people who will be facilitating the AI paradigm in the first place.
Still, there was one pair that stuck out while I was researching:
ComplAIning to HR
I spoke a lot about the impact of AI on personnel management firms and talent acquisition companies, as AI/ML made existing employees more efficient and rendered some temp jobs unnecessary. This was a much longer term impact, but - as you’re probably aware by now - playing the perception of a theme is just as important as playing the theme itself. With that being said, my favorite long/short pair in this area has been focused on the companies in this space which are more effectively utilizing AI vs. those which are not. The best implementation of this specific AI play so far as been long Recruit (6098 JP) vs. short Manpower Group (MAN US).
Recruit has been taking AI very seriously, with recent comments from management showing that they understand exactly how important it is to ensure they’re prepared for the changes it will bring:
So to answer your question, the investment in this area is despite the good or bad economic times, we have to do, we have to invest, no matter what. And we have the strong commitment because we think we are the only one who can do this in the HR industry and for a brighter future. I hope we can share with you some more specifics in the future.
A long position in Recruit Holdings and short position in ManpowerGroup makes sense when considering Recruit's progress in applying AI for talent acquisition and HR. Recruit is actively utilizing AI to increase automation and efficiency in HR processes like screening and matching candidates to open positions. This includes natural language processing to parse resumes/profiles and machine learning algorithms to determine fit.
By contrast, ManpowerGroup still relies heavily on manual efforts and human consultants for recruitment, without similar AI capabilities. This leaves them lagging in terms of productivity growth and cost structure.
Recruit's management sees major room for continued improvement in HR through AI adoption since legacy processes were slow and labor-intensive. Automation can drive much higher throughput of placements while reducing staffing overhead. Over time, Recruit's AI-enabled offerings could gain market share from Manpower's human-driven approach by offering greater speed, personalization and cost advantages.
This specific play has been doing quite well and I expect it to continue as Recruit’s investments yield results.

Can Cloud Providers overcome the AI Cannibalization?

Digital Ocean (DOCN US)
In Cloud, I have been following DigitalOcean. DOCN was a name that could easily be disrupted by AI-related cloud spend “cannibalization”, but ultimately seems to have recognized this and begun aggressively focusing capex spending on expanding their AI/ML capabilities.
DOCN’s launch of Managed Kafka service and their integration with Paperspace (following the acquisition) expands DigitalOcean's capabilities in powering AI/ML workloads. Kafka is commonly used for streaming data pipelines and model training workflows, while Paperspace provides GPU access needed for AI model development. This will drive incremental growth as AI models become more accessible to SMBs due to model commodification and the decreasing cost of tokens. Enabling AI/ML workloads allows DigitalOcean to better compete with hyperscalers like AWS and Azure in the SMB segment. Having Kafka managed service and GPU infrastructure closes a gap compared to larger cloud providers. DOCN’s investments in AI-related infrastructure could help increase retention of high-value customers by giving them needed capabilities on DigitalOcean platform rather than going to multi-cloud deployments.
While a core focus for me on the “AI Losers” was that companies without the capability to absorb the necessary capex spending to compete in AI would suffer, DOCN reported last quarter that despite taking on additional expenses from integrating the Paperspace business post-acquisition, DigitalOcean kept profitability metrics within target ranges. This implies they are finding synergies from bringing Paperspace GPU cloud capabilities in-house and managing spend.
To quote their earnings call,
…our margin profile for the core DigitalOcean business was very strong for the quarter and enabled us to absorb the incremental cost from our Paperspace acquisition, while remaining within our targeted range of adjusted EBITDA and free cash flow margins.
An anecdote shared on the call stood out in the context of LLM commodification:
To give you a sense for one such use case, I'll provide an overview of 1 of the exciting customers we recently added to the Paperspace platform. The company is Nomic which was founded in 2022 to improve the explainability and accessibility of artificial intelligence. Today, Nomic has released 2 products: an open-source AI model, GPT4ALL, which is which is the third fastest growing repository in GitHub history and Atlas, a tool that allows users to visualize unstructured datasets used to build large language models.
Nomic selected DigitalOcean excess high-performance compute, along with our intuitive software, customer support and reliability. Their co-founder was quoted as saying, our team loves Paperspace. It's far more intuitive than other compute providers. It allows us to spend less time managing infrastructure and more time building great products for our customers. Their testimony to DigitalOcean's combination of simplicity, reliability and support along with the current demand environment that we see excite us for the opportunity ahead. The RFPs that we are seeing span across multiple verticals for multiple applications and demonstrate the opportunity for new customers to join our platform to not only build their AI applications but also to scale their products while utilizing the breadth of our IaaS and PaaS capabilities.
The Redistribution of Wealth for the GPU Poors?
As AI becomes more accessible, these 'GPU poors'as my esteemed colleague Dylan Patel 2 calls them (companies that previously lacked the resources to invest heavily in top-tier GPU hardware) are now finding the playing field more level.
The reason behind this increased spending is twofold. Firstly, reduced costs remove a significant barrier to entry, allowing a wider range of companies to invest in AI. When costs are prohibitively high, these companies are not just limited in their AI capabilities; they are effectively excluded from the AI market, resulting in zero revenue for AI providers from this segment. As costs decrease, these companies are not only able to enter the market but are also motivated to invest more in AI to catch up and stay competitive.
Secondly, the relationship between AI affordability and increased spending is not merely about the initial investment in AI technology. Lower costs also enable companies to allocate funds towards customization and innovation in AI, tailoring solutions to specific industry needs and creating novel applications. This is particularly relevant in sectors that have unique requirements or have been slower to adopt AI due to cost constraints. As AI becomes a more integral part of their operations, these companies are likely to increase their spending
Right now, you can fine-tune a 7 billion parameter model for about $10 using 8x NVDA RTX 4090 GPUs (all-in cost w/ mobo+cpu+psu etc. of about $13-15k).
Are the most exciting and cutting edge technological leaps in AI going to be enabled by fine tuning a 7b model? No. But this kind of progress not only makes AI more accessible but also allows for more experimentation and innovation at a lower cost. The ability to fine-tune large models affordably opens up new possibilities for companies to explore complex AI solutions that were previously out of reach due to financial constraints. This will result in the proliferation of consumer use cases by smaller players, while the larger ones focus on the cutting edge.
In essence, commoditized LLMs turn into a volume play, benefiting scaling and, while the tools may get commoditized, the talent, customization, governance and infrastructure to optimize application of LLMs retains differentiation. First-mover standalones without these complementary assets struggle most against "AI-as-a-service" trends. Collaboration amplifies commoditization rather than competition alone (too much alliteration, sorry). At the end of the day, the AI cut into cloudspend is going to be nuanced.
Cheaper LLM tokens and more efficient fine tuning are not the only reason that AI will become more democratized in the immediate term. If you speak to developers in areas of AI that rely heavily on real-time datasets (who have been struggling somewhat with the cost of training and the high incidence of hallucinations), many of them are mentioning that RAG has become a good solution.
Retrieval Augmented Generation (RAG)

RAG is essentially real-time training. It integrates the strengths of generative AI models with external data sources. In traditional language models, the knowledge is limited to what was included in their training datasets. RAG, however, can access and incorporate external, up-to-date information in real-time, essentially broadening its knowledge base beyond its initial training. This makes RAG-equipped models more adaptable and knowledgeable, as they can pull in recent data or information from specified databases to enhance their responses.
By utilizing external data sources, RAG can provide responses that are not only more accurate but also more contextually relevant. This is particularly beneficial in industry-specific applications where staying current with the latest information is crucial, such as news aggregation, market analysis, or medical research.
The key benefits of RAG are:
Reduced Hallucination Rate: By incorporating external, factual information, RAG reduces the likelihood of generating inaccurate or nonsensical responses (hallucinations) common in LLMs.
Current and Detailed Data: RAG enables LLMs to provide up-to-date information without the need for additional fine-tuning, overcoming a major limitation of LLMs that are usually static and outdated shortly after training.
Simplicity of Implementation: The operational mechanism of RAG is relatively straightforward, allowing for easier integration and use.
Traditional AI models require extensive retraining to update their knowledge, which can be resource-intensive. RAG models, by dynamically pulling in information from external sources, can stay updated without the need for constant retraining. This reduces computational costs and makes AI models more sustainable and easier to maintain. The ability of RAG to pull in data from various sources simplifies the process of creating advanced AI applications. Developers and businesses without deep AI expertise or access to large datasets can leverage RAG to build sophisticated AI tools. These kind of developments are key to democratizing AI, allowing a broader range of users to develop and benefit from AI technology.
It is highly likely we will begin to see AI being implemented much more broadly due to RAG and similar ease-of-use and broader use case applicability tools, as it becomes increasingly accessible. There is already evidence (sourced from channel checks at CES and my own experience at JPM Healthcare) that the impact of ML, DL, and Generative AI is spreading to microvertical areas such as health, medicine, agriculture, entertainment, and beauty.
The fact of the matter is, despite the emergence of Generative AI, most companies are still at the conventional AI level, for example, still using CNN technology rather than transitioning to ViT. Because of this, it is still to early to assess the direct impact of AI throughout the broader economy and ex-tech industries - but it’s likely we will encounter many of these early developments in 2024.
As Jensen Huang said of industry specific datasets, companies with vast data are “sitting on a goldmine”, RAG will enable them to mine the gold. Two standout beneficiaries here are Experian and SPGI. Yes, they’re a bit less exciting than the rest of the AI beneficiaries, but it’s likely they’ll be some of the first to see sustained EPS increases from Artificial Intelligence outside of Phase 1.
I believe we will start seeing many more use cases for AI emerge in the second half of 2024, and it’s likely to pay off paying attention to headlines surrounding them as they are launched by adopters.
The adjustments to the AI basket will primarily focus on positioning for a more advanced progression of Phase One and anticipate Phase Two/Three to pick up steam in 2024.
Before we get to the specific adjustments, I think it’s important to evaluate how the adjustments we’ve made thus far have performed (to determine whether we should simply leave it alone or if our slight changes have lead to outperformance).
AI Basket: New Members & Weightings
You can view our updated AI basket exposure in our core portfolio allocation by going to our Citrindex tab on the home page:
You can view the performance of all the names listed in the original AI basket since the date of publication here.
AI Basket: Adjustments
Summary of Changes:
DELETIONS/REDUCTIONS:
We exit the following positions and rebalance any remaining weighting after additions across all holdings. We’ve reduced exposure to some Taiwanese names we think are either redundant or not thematically pure, to reduce China risk across the core portfolio. These were either too ambitious on the overall thesis, are now redundant as a competitor is outperforming them (and expected to continue doing so) or have not materialized with the anticipated AI benefit:
2327 TT
2317 TT
3264 TT
3540 TT
3594 TT
6282 TT
6324 JP
6526 JP
6656 JP
COTN SW
ENTG US
EXTR US
FORM US
LFUS US
MRN FP
SDGR US
SNX US
ST US
TEL US
VICR US
WAF GY
M&A Deletions: VMW US & ANSS US
REDUCING WEIGHT BY 50%:
We REDUCE AND UNDERWEIGHT the following positions in the semicap space (which may be facing some challenges in the next year, and is relatively priced to perfection)
AMAT US
LRCX US
ASML US
We REDUCE the following position not out of bearish sentiment but to take profit on an earlier significant overweight during October 2023, bringing it back to portfolio weight:
MPWR US
INCREASING WEIGHT BY 50%:
We INCREASE the following positions in the memory space (which seems to have bottomed and will see significantly more demand than currently priced in)
MU US
000660 KS
PHASE ONE NEW ADDITIONS:
CIEN US
COHR US
2454 TT
6669 TT
QCOM US
WDC US
We also trim back any names that have been above concentration limits of 400bps (AAOI US, NVDA US and SMCI US have all exceeded this since our last rebalance, and are anywhere from 6-800bps). Remember that the point of our baskets is not to capture one specific company’s prospects due to AI but entire sectors and subsectors experiencing tailwinds. These new additions will make up around 15% of the basket but the entire basket is not changing much.
Additionally, because of the sharpe of the AI trend right now, I’m implementing the AI basket with some modest leverage, which brings net exposure for the AI Longs basket up to +118%. We will seek to bring that down as we take further profits.
This has been an extended preview, to see the rest please become a paid subscriber!
Evaluation and Review of Previous Adjustments to Portfolio AI Exposure
Evaluating Adjustments to AI Longs Basket (from “AI: Global Equity Beneficiaries”)
Long-time readers will recall that I have only adjusted the weightings of our AI longs twice, and so far not adjusted the individual names in the baskets since they were published back in May.
The first was here, on October 30th 2023 when we brought up our allocation from 11% to 15% and overweighted MPWR.
The second time was when I broke out MRVL as a standalone long (from our thesis here in 24 Trades for 2024) and pared back the AI Shorts by 1/2 down to 3% weighting:
EXIT AI SHORTS
It is simply better to bring up the net exposure here I believe & as this rally broadens out we risk getting squeezed. I may put the shorts back on before earnings.
Evaluating Adjustments to AI Long/Short Basket (from “Less Deus, More Machina”)
On November 7th 2023, we exited and took profits on our AI Long Winners/Short Losers basket:
Let’s weigh whether that was an appropriate call. Here’s how it performed since:
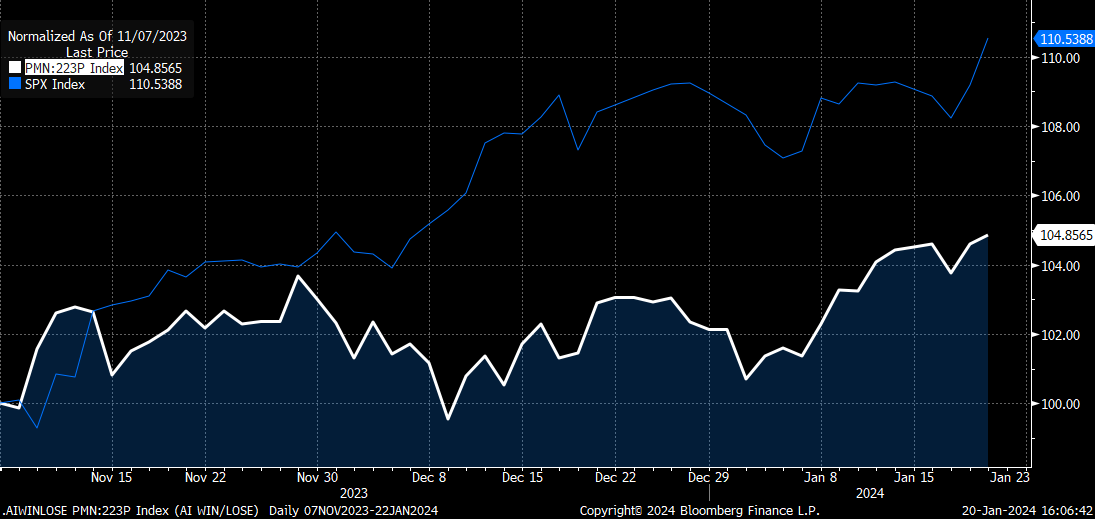
So, while the longs still did continue to manage going up more than the shorts, the total return of the basket was much less than the S&P500 (which I benchmark long/short to, even though prevailing wisdom is to benchmark it to T-Bills).
A few developments had occurred in the software & AI space that I had not anticipated, and rather than continue to take such a granular view into what I expected would be continued market strength, it seemed prudent to have our net exposure higher and not take more risk than necessary on long/short AI until the trend had played out further. The thing about a play like this is one must remain mindful of both the theme, but also the broader market environment. I expected that the next few quarters would be a bad one to be short anything, even L/S, if one wanted to outperform the benchmark, that ended up being the correct intuition.
Evaluating Adjustments to AI Shorts Basket (from “Less Deus, More Machina”)
There has only been one adjustment to the AI Shorts basket.
On November 8th, 2023, we took profit on EXFY after it was down 75% from where we first went short:
The AI shorts basket was primarily meant to ensure that the volatility associated with the relatively high beta of the names in the AI longs basket wouldn’t contribute to undue volatility. While the basket performed quite well in the beginning, it ended up losing most of the gains when we encountered a bit of a short squeeze towards the end of the year.
However, it served its purpose and the AI longs distinctly outperformed the AI shorts over the timeframe we’ve had them on:
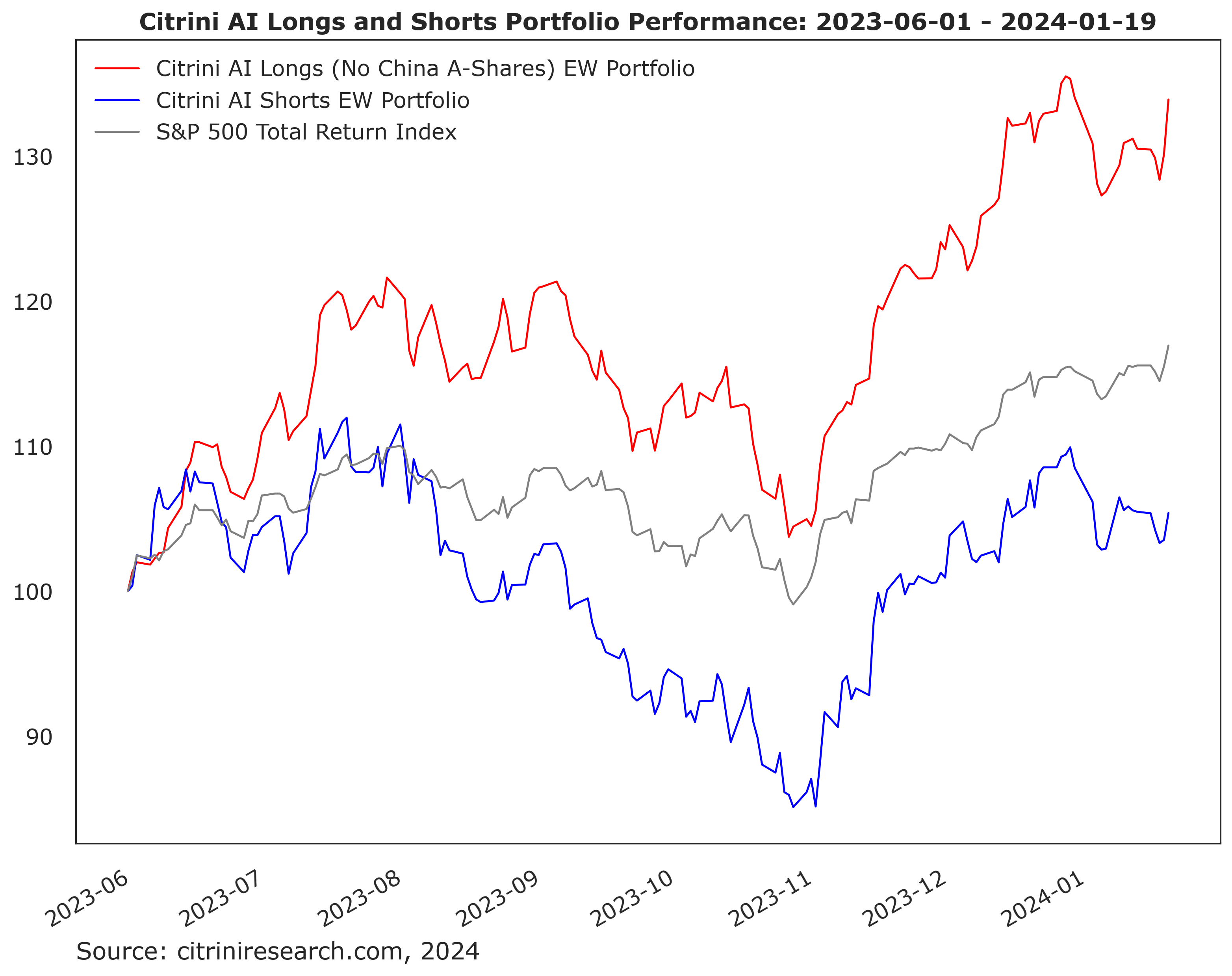
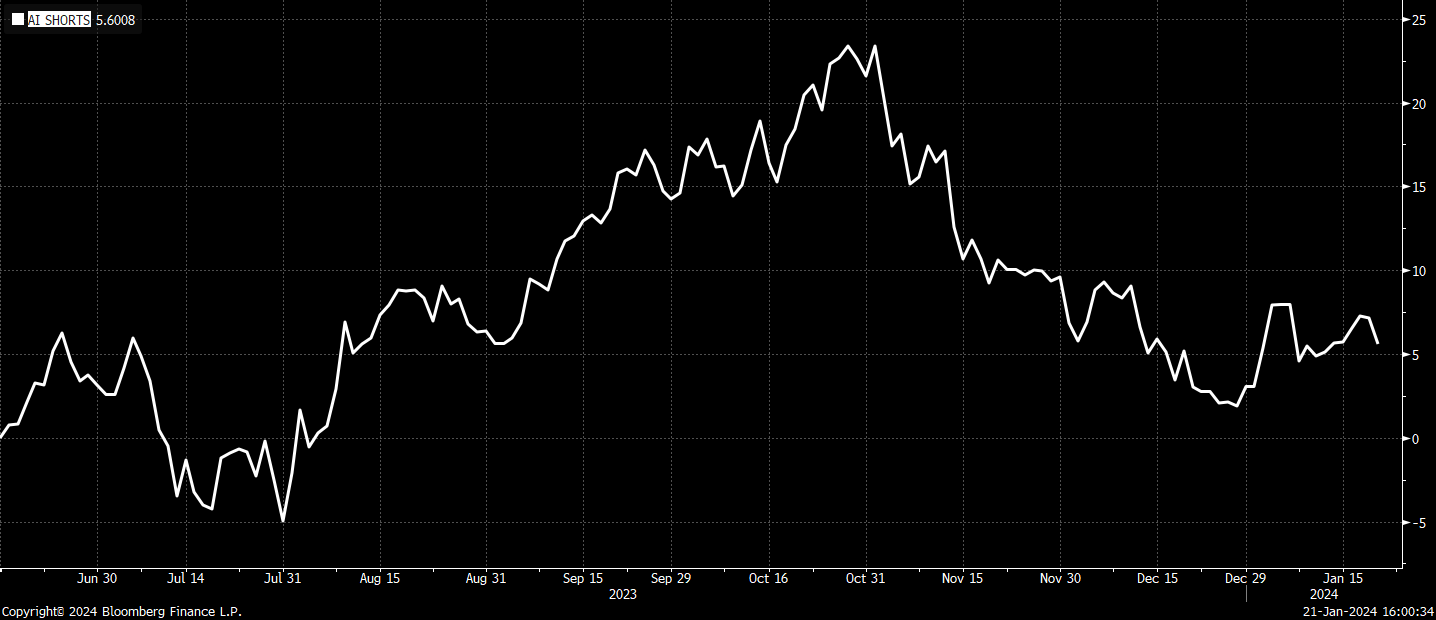
Due to the anticipation that this rally will broaden out, with bulls emboldened by lower rates and - now - new ATHs on SPX, I recently pared it back from a 6% allocation to a 3% allocation. Other than taking profit on a single name
GLP-1s and Weight Loss Trends
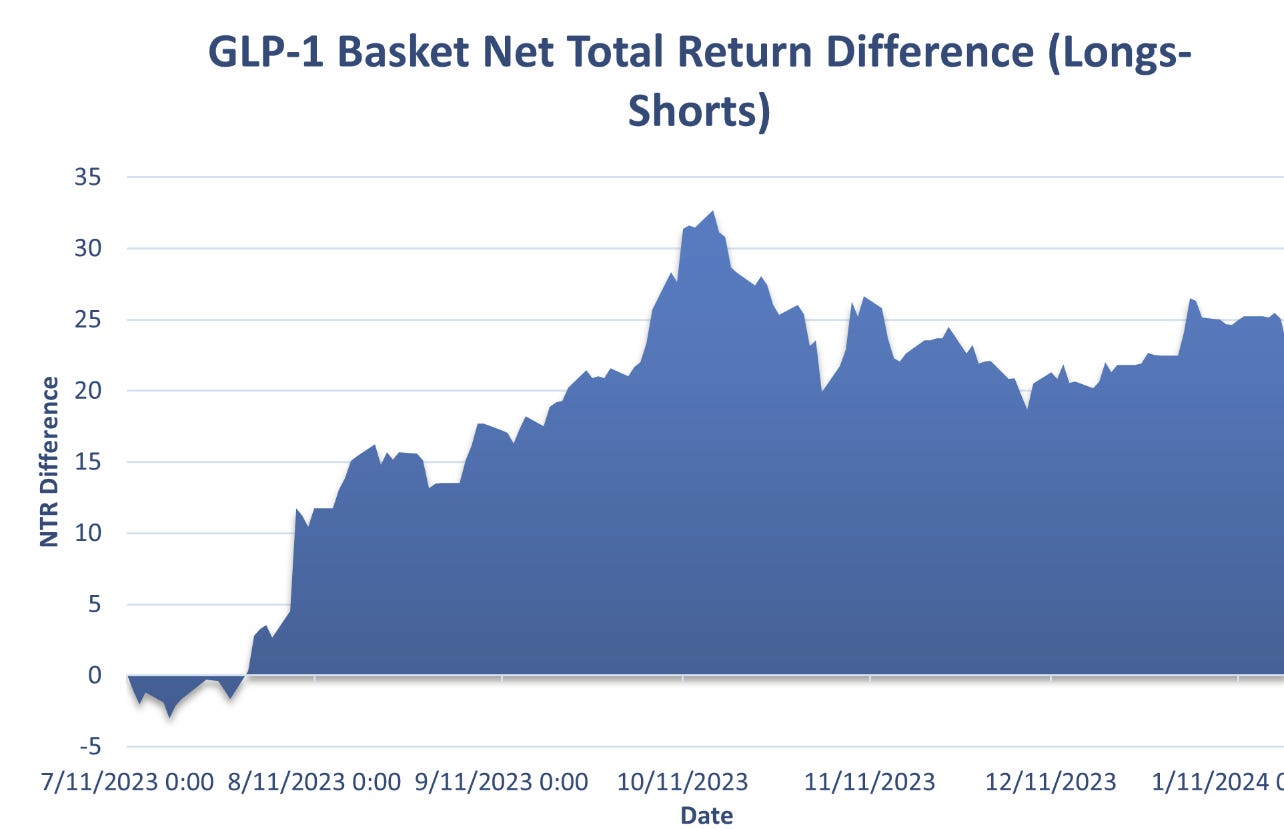
The GLP-1 Basket has also been quite successful, and the theme has been more than confirmed by data and renewed expectations.
In the last thematic update, all the way back in August 2023, I said the following:
“In 5 years time, long LLY short RMD will be viewed in the same way we view long Apple short Blackberry.”
-CitriniResearch.com Article: “Market Memo: Enter the Titan Stapler” (August 8 2023)
It hasn’t been 5 years, but the charts of some of these pairs are starting to take on a familiar look:
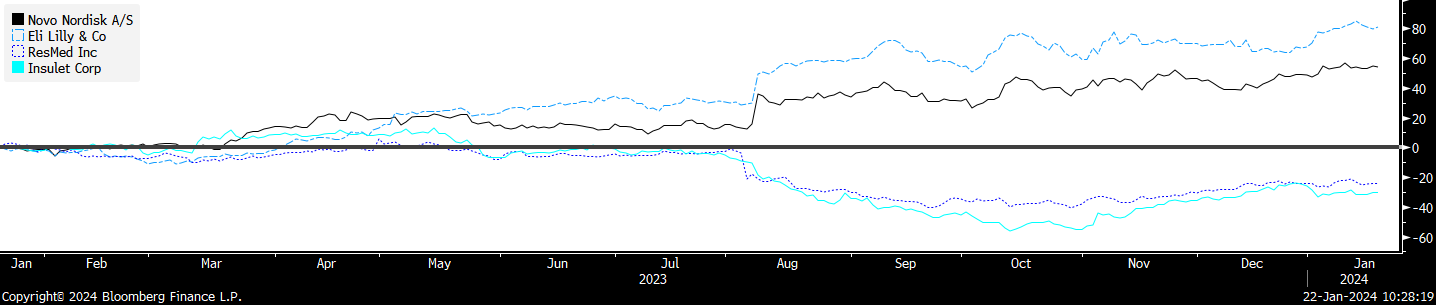
GLP-1 Supply and Demand
At the JPM Healthcare conference, GLP-1s were the subject of a lot of speculation, but probably the most interesting thing that happened related to this basket was the fact that I spoke with someone at Nestle who told me they were already taking steps to diversify away from their junk food portfolio in the US due to the anticipated impact of GLP-1s. Although the performance of the basket was enough to validate me, hearing that was a pretty big moment after having put myself out on a limb urging investors to consider the secondary and tertiary effects of these drugs.
Eli Lily (LLY US) has released its drug Zepbound at a 20% lower price point than Wegovy, and is using the same coupon strategy that it used during its Mounjaro launch to penetrate the market. This is worth keeping it mind as it may result in the next two quarters Zepbound revenue being misleading for projecting out. It’s likely to outpace Wegovy’s uptake.
The bottom line was summed up well by LLY’s CEO at JPM HC: there’s about 500,000 people taking these drugs in the US, and more than 100 million who could or should be.
The real winner in the GLP-1 market will likely hinge upon which company gets the most effective oral formulation that can meaningfully substitute for injectables, not just in weight loss but also side effects. This is not because patients dislike autoinjectors - evidence shows they generally don't mind and some prefer weekly dosing. Rather, an oral tablet with a small molecule drug could significantly increase supply to meet the current 100x demand vs supply imbalance.
Eli Lilly's first new manufacturing facility is online and ramping up, currently assembling auto-injections with fill-finish capabilities expected shortly. This should double Lilly's capacity once fully operational. Their second plant remains on track for late 2024 and is a similar size, further boosting supply. Additionally, ex-US, Lilly plans to introduce vials and later multi-dose pens with 4 doses per pen in 2024, also improving availability.
So while innovations like vials and pens may provide some alleviation, the potential for an oral formulation to radically scale supply underpins the biggest upside for major players in capturing unmet demand within the GLP-1 market. Rather than delivery mechanism, the oral route likely determines the ceiling for sales growth.
In the meantime, capex focused on expanding supply for GLP-1 autoinjectors is up significantly.
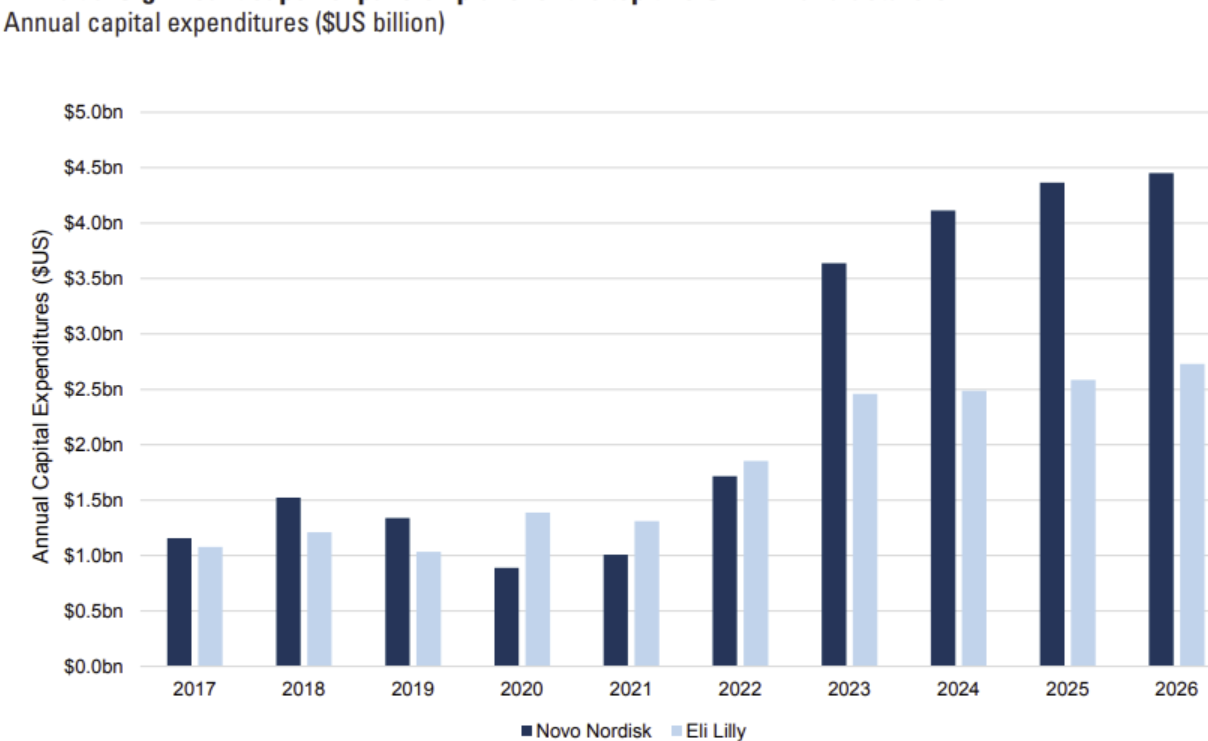
If one company wins oral, or makes a massive stride in supply, while the other doesn’t - that would pose a huge risk to current expectations. While LLY’s pipeline is more promising in almost every aspect when it comes to injectables, NVO does seem to have the edge here with oral amycretin. Refer back to the GLP-1 section of the “24 Trades for 2024” article to read my thoughts on LLY’s orfglipron.
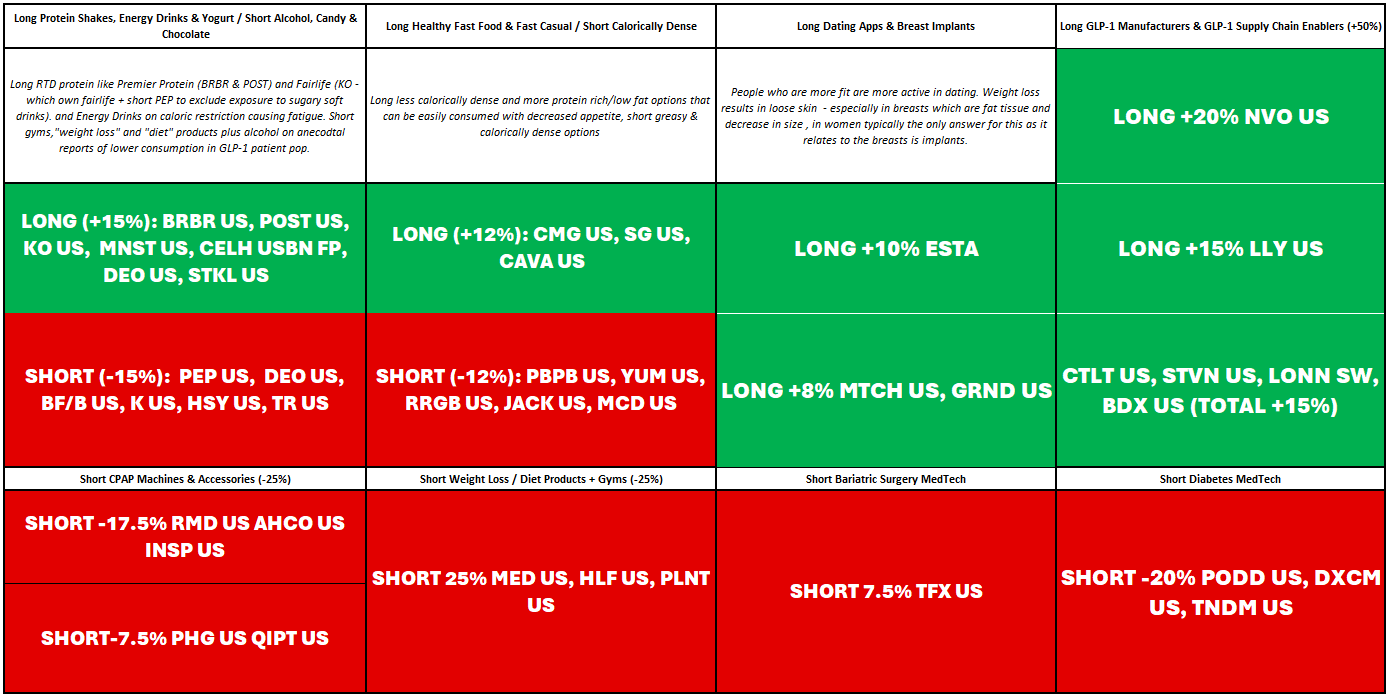
New Long/Short GLP-1 Categories
Updated
This is our revised GLP-1 Basket for 2024:
One thing I’ve found interesting in monitoring keyword mentions across the GLP-1 subreddits and facebook groups is increasing mentions of protein supplementation. Primarily interest seems to be in ready-to-drink (RTD) protein shakes:
..and yogurt:
Because reddit has made it more difficult to scrape the site, it’s hard to get a chart showing mentions but I have some tools I use and they’re confirming mentions of both of these staples categories have gone up. We are already short some “weight loss” health food names mentioned in the original GLP-1 article (MED US, HLF US) and as this theme has developed I’ve come around to the thesis on RTD protein shakes as well as health food.
The GLP-1 basket has gotten more concentrated (not a bad thing, primarily it’s the result of NVO/LLY doing so well and us having taken profits in our MedTech shorts back in November as many were down 40-50% and rates threated to have them squeeze back up). It’s also become about +50% net long, that’s been nice to take advantage of the large increase in I’d like to broaden it out again.
We have our high conviction names (with one added below), and now I’m adding back some “GLP-1 Beta” names to get the basket back to market neutral.
Here’s what I’ll be doing:
a) Long RTD Protein Shakes & Yogurt vs. Junk Food CPG
b) Healthy Fast Food/Fast Casual vs. Unhealthy/Calorically Dense
c) Adding back MedTech Shorts: We took off the medtech shorts at the end of october fearing that the move up in rates was exhausted and would reverse violently, which occurred - because of MedTech’s rate sensitivity many of our shorts also rallied, but I have been watching to see when they get extended as our specific medtech names still face significant headwinds from GLP-1 drugs. Additionally, as improved odds for oral increase the chances that supply will be able to meet demand and these second order effects will materialize on a faster time frame, making sell side estimates for penetration look very low.
and
d) Energy Drink & Yogurt Longs / Alcohol Shorts. On the long side, the reason I mention this is because I was speaking to Tracy Alloway of Odd Lots who recently interviewed the CEO of Celsius Energy. He talks about Ozempic users possibly needing energy drinks to compensate for fewer calories, which I believe is a valid view (caloric restriction and GLP-1s have had some patient complaints about fatigue). Additionally, the data has piled up (anecdotal but in significant volumes) about GLP-1s resulting in less drinking by patients. Not just that, but gen Z seems to put less of a priority on drinking and - while unrelated to our GLP-1 theme - that seems like a thematic headwind double whammy.
See below for the names included in these categories.
GLP-1 High-Conviction Addition: Long ESTA US
Keeping you abreast of the situation with our GLP-1 basket, I already teased this new addition in the chat:
We are adding Long ESTA as a GLP-1 secondary beneficiary at a 7.5% weight, considering my expectation that breast augmentation surgeries will see a surge in volume off the back of higher than modeled weight loss and the effects weight loss has on extra skin / breast size.
Plastic surgery volumes have already been impacted positively by weight loss due to GLP-1s. The results from a quick google search show that plastic surgeons are already marketing to this segment:

And here’s some more color from Dr. Cori Aggarwal, a cosmetic surgeon who was interviewed on the subject of breast augmentation surgery after weight loss by the University of Utah Health Library:
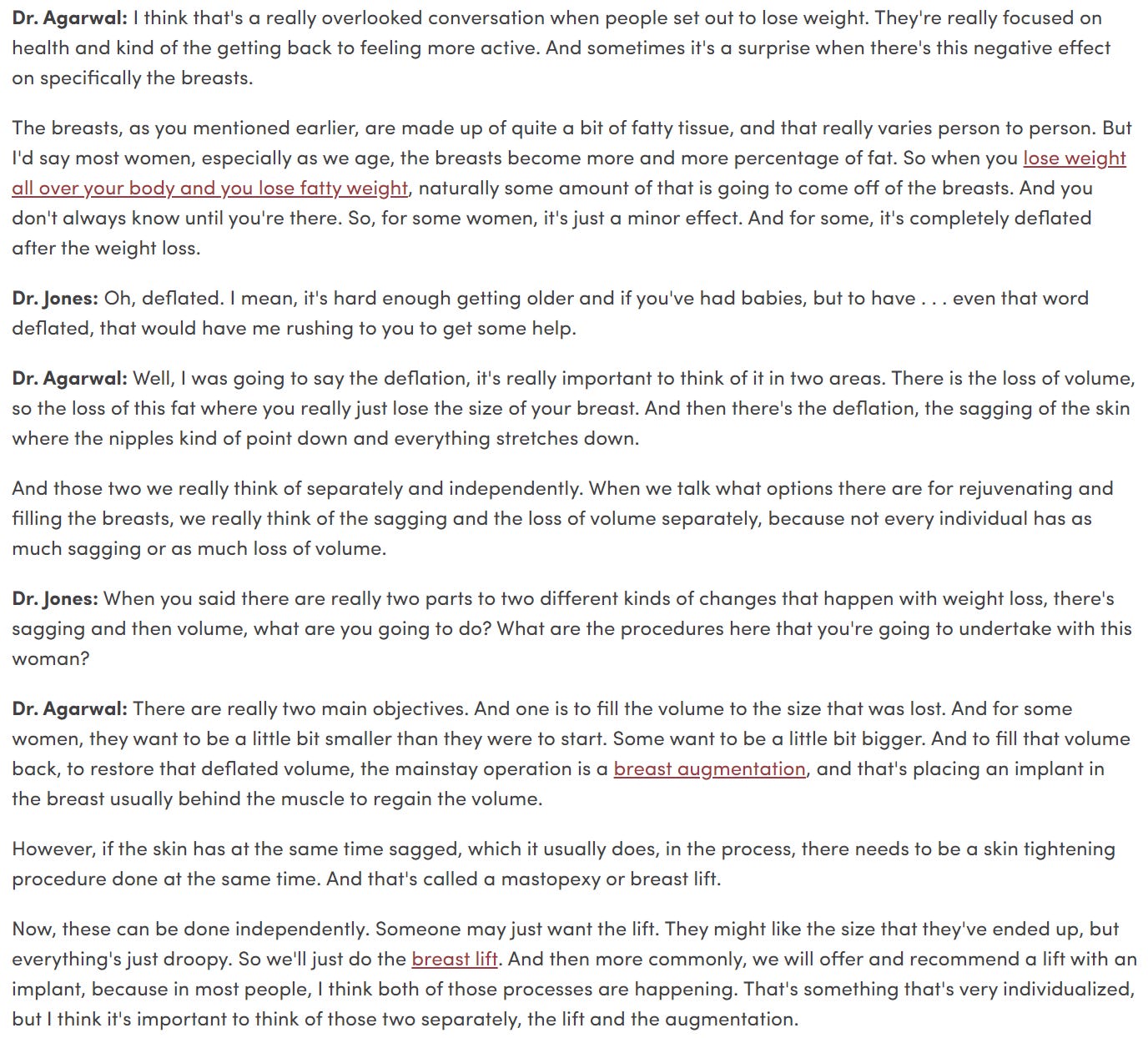
It’s important to highlight that the most common offering is both the lift and the implant.
Something to consider here is that most breast augmentation / breast implant surgery is viewed as cosmetic and not covered by insurance companies. That is actually, in my view, going to make the current GLP-1 environment even more of a tailwind to surgical volumes for implants. Recall that many insurers are not covering GLP-1 drugs, and the high cost out of pocket has resulted in most of the current TAM being in the upper two quintiles of earners.
The venn diagram between “people willing to pay $1,000+ per month for an effective weight loss drug” and “patients willing to pay out of pocket for cosmetic surgery to be satisfied with their appearance once they’ve been successful with weight loss due to that drug” is pretty much a circle. This is an additional tailwind for ESTA as their Mia platform is the highest cost option per patient, and has the potential to deeply penetrate the highest brackets of disposable income.
Breast augmentation has turned positive year over year for the first time since 2021 in the last two quarters, perhaps attributable to the wealth effect (I don’t believe this is yet attributable to GLP-1s, although future growth against the easy comps of 1H 23 may be):

The largest players in the breast implant space are JNJ & ABBV, but they are definitively and obviously not pure plays. Establishment Labs (ESTA) is a riskier option, as an unprofitable medtech company focusing heavily on innovation, but one that I believe will work. After all, going from bad to less bad due to thematic tailwinds has always been a great driver of returns for me (see: AAOI).
I saw ESTA speak at the JP Morgan Healthcare 2024 conference,
Significant growth opportunity from China market entry and minimally invasive Mia rollout
Significant growth opportunity from China market entry
Significant growth opportunity from minimally invasive Mia rollout
Strong safety and differentiation of Motiva driving premium pricing and market share gains
Mia is the highest pricing per patient offering. Mia aims to be a unique minimally invasive approach leveraging the Ergonomix2 Diamond implant enabling (a) procedure times closer to 15 minutes versus 60+ minutes traditionally; (b) use of local anesthesia instead of general; and (c) shorter recovery times of days instead of weeks with return to activities the same day. The pricing and nature of this product is what makes me think ESTA will see significant tailwinds from GLP-1s more than anything.
Line of sight to profitability while maintaining >20% revenue growth
Expect to hit EBITDA profitability before the end of the 2024 and then cash flow profitability by the end of 2025
They had a very interesting video displaying the differences between the insertion of their implant and their competitors, but I have not been able to find it online yet (it’s possible it hasn’t been uploaded yet). You can read the transcript of their presentation here:
Trade Retrospective: Reviewing Prior Decisions on GLP-1 Exposure
Since publishing it on July 11th 2023, I have adjusted the GLP-1 basket three times.
The last time I updated on these adjustments was here, but I will go over them again for new subscribers who haven’t followed the saga and to revisit whether those adjustments were good ideas.
As you probably know by now (I won’t shut up about it, I know), it’s always been important to me in terms of evaluating strategy to look back at the decisions you made not just in light of the performance of what you bought but of what you exited. Entering a play that goes up 15% is great, unless you sold a play that went up 50% to get into it.
GLP-1 Adjustments Since Inception:
First, on 10/13/2023, we made adjustments to the GLP-1 basket that reduced short exposure by half to all the Med Tech components in the basket. This reduced AHCO, PHG, PODD, INSP, QIPT, RMD, TFX & TNDM and increased the basket to a net long exposure of about +30%, which I described here:
The reduction of the MedTech shorts on October 13th 2023 was a good decision, my reasoning that interest rates would decline and that a portion of the decline in MedTech was due to rates rather than GLP-1 impact was proven correct as a large rebound occurred.
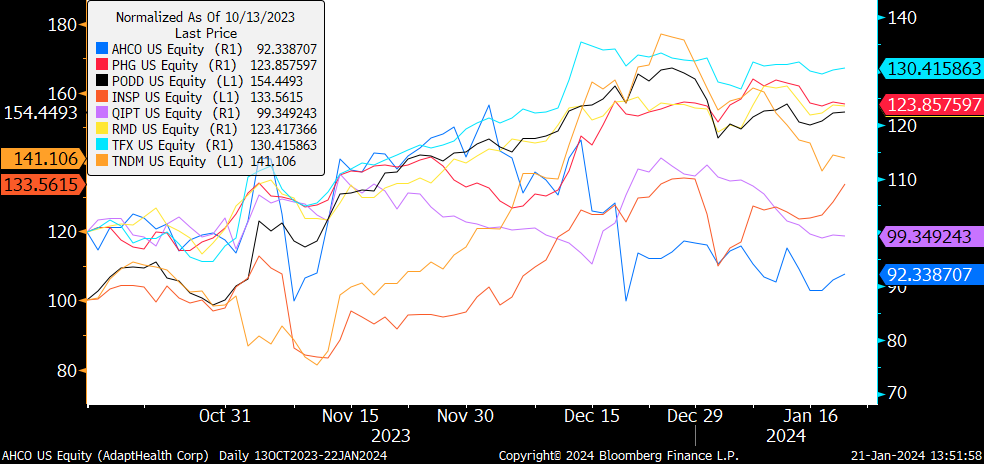
The average increase in the GLP-1 MedTech shorts was +24.79% since we decided to reduce them by half.
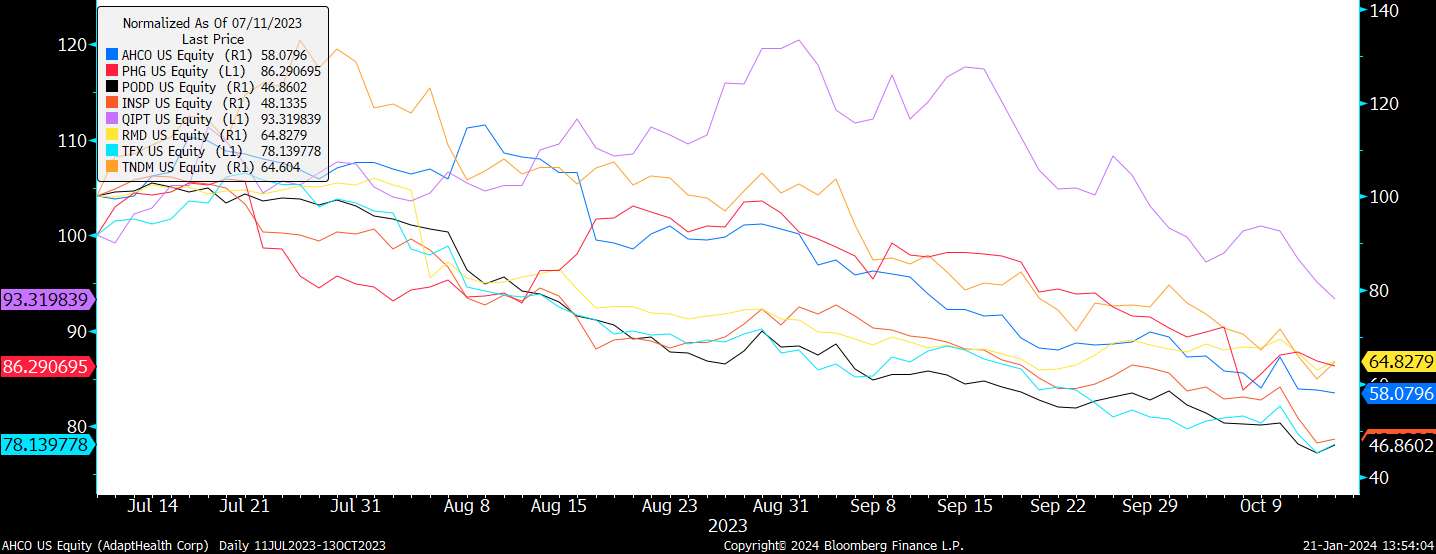
That compares to an average decline of -32.47% between the time we put on the basket (July 11th 2023) and the time we reduced short exposure to MedTech.
Honestly, I should have exited them completely but I wanted to have some hedge against the market continuing to decline and getting the basket too net long would have worried me with too much market beta.
Second, on 11/08/2023, we initiated a new long on ATS US and deleted the long on DXLG US.
The addition of ATS upon the exit of DXLG was another good decision, with ATS up nearly 15.8% and DXLG down 7.42% since.
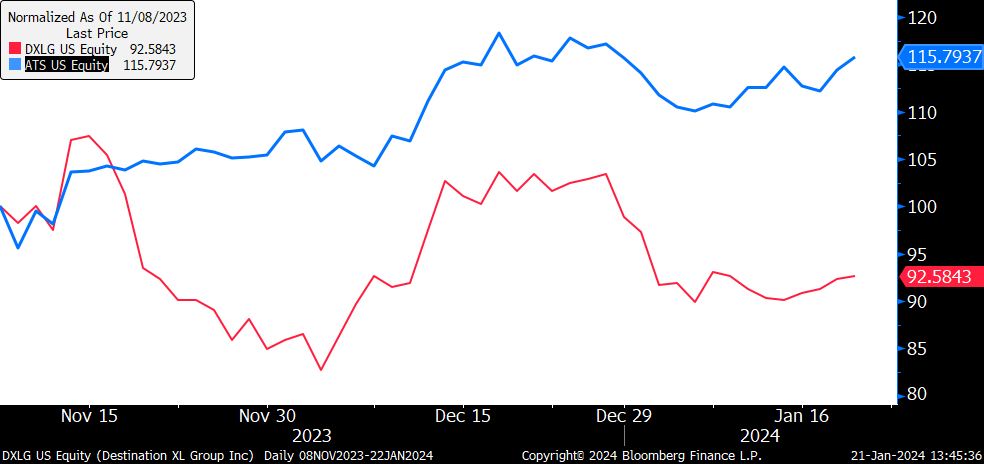
However, ATS has some EV exposure which can cause it to sell off and kind of excludes its GLP-1 pure-play-ness, so I am going to replace it with Lonza (LONN SW) and Catlent (CTLT US). LONN is not exposed to peptides directly, but could do fill-finish for peptides.
I’m quite glad that my analysis led me to exit DXLG rather than CURV, as they have similar theses (just the latter is gender specific to women). I believe, anecdotally, that GLP-1 adoption in women is “stickier” and leading to more spending & lifestyle changes. We can see that it would have been quite ill-advised to cut CURV when we cut DXLG, despite the fact it was dragging down our performance at the time.
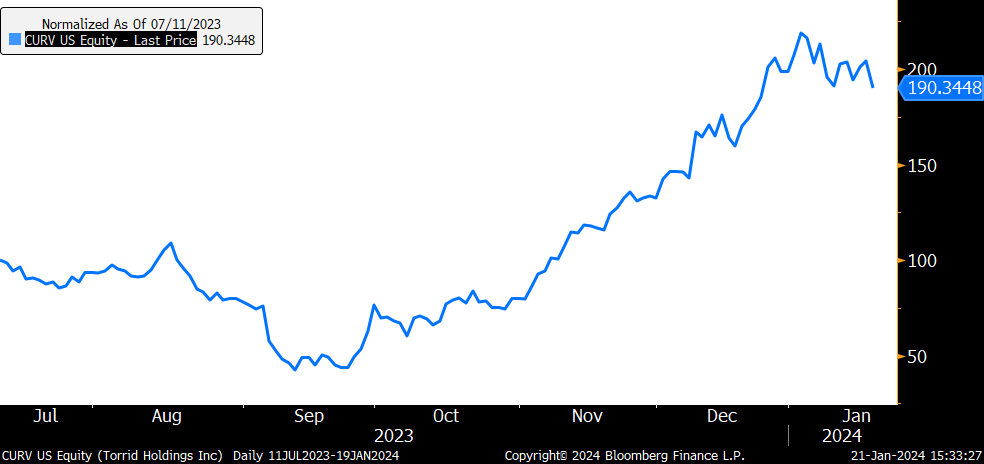
Still, I think this move is probably close to exhaustion and any incremental benefit from GLP-1 driven wardrobe demand from women is probably already priced in.
I’m looking to get back to being short GLP-1 medtech now that the worst of the lower rates rally is likely over, also we now have rates exposure on our biopharma plays that I’d like to hedge a bit.
OTHER CORE PORTFOLIO CHANGES
PUTTING A STOP TO CHINA
Actually, just putting a stop loss on China. Our Chinese equity basket, specifically. I’m not throwing in the towel just yet, because we haven’t taken that bad of a drawdown.
I’ve held out hope for a while that China would turn around, and I was pleasantly surprised by the relative outperformance that our savvy stockpicking & well timed FX hedge in the Chinese Equity Barbell Basket provided us with. For most of the course of this play, we have been above our cost basis despite dismal performance on the broader Chinese Equity indices.
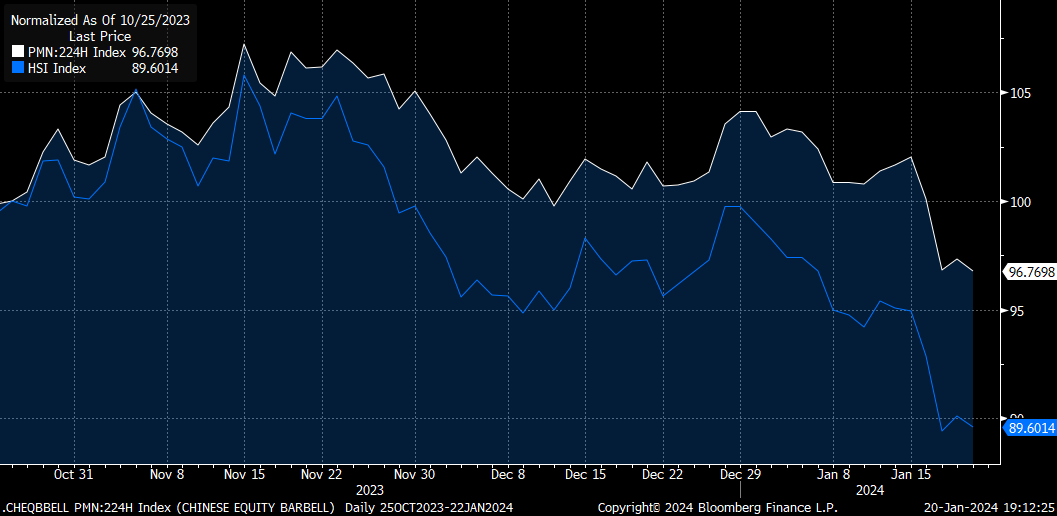
Unfortunately, not even good stock picks was enough to save us from the wrath of the dragon. We’ve finally gone below our cost basis as of this recent cascade of margin calls in the Chinese market following the fallout of some structured products voodoo and China’s insistence on continuing to deleverage.
While I’m not throwing in the towel just yet, it is never a good idea to be in a play where you don’t have an eye on the exit. Currently, we are down 3.24% on our basket (and, of course, the cost should also be taken in light of the opportunity for gains we could have had allocated elsewhere), which is better than the -10%+ drawdown had we allocated to the Hang Seng, but still - it’s time to get serious and define risk here.
If this drawdown goes below -9% I will be cutting the Chinese Equity basket. In order to facilitate this expected risk, I’ve reduced the size of the Chinese Equity Barbell down to 9.25% (previously ~10%).
It’s do or die time for China as far as I’m concerned, either that last capitulation marks the bottom / damn near the bottom and gets the government to intervene or I’m going back to treating China as dead money. I have no qualms about admitting I was wrong, that’s part of trading. While we aren’t allocated to the Hang Seng, I feel safe saying that our stop on all our China exposure is triggered on a daily close for the HSI below the lows made during last night’s session (about 14,960).
In the grand scheme of things, the underperformance in China hasn’t hurt us too badly.
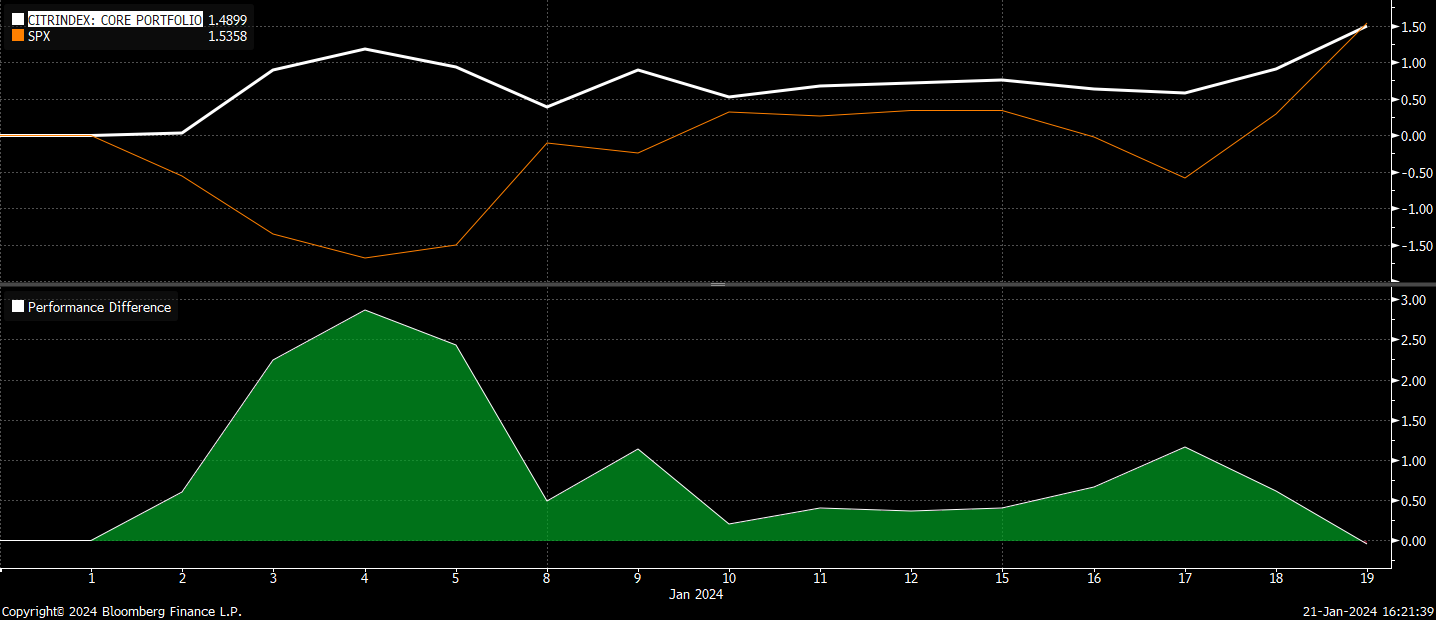
The CitriniResearch core portfolio is up 65.2% since inception, beating the SPX by 48.52%.
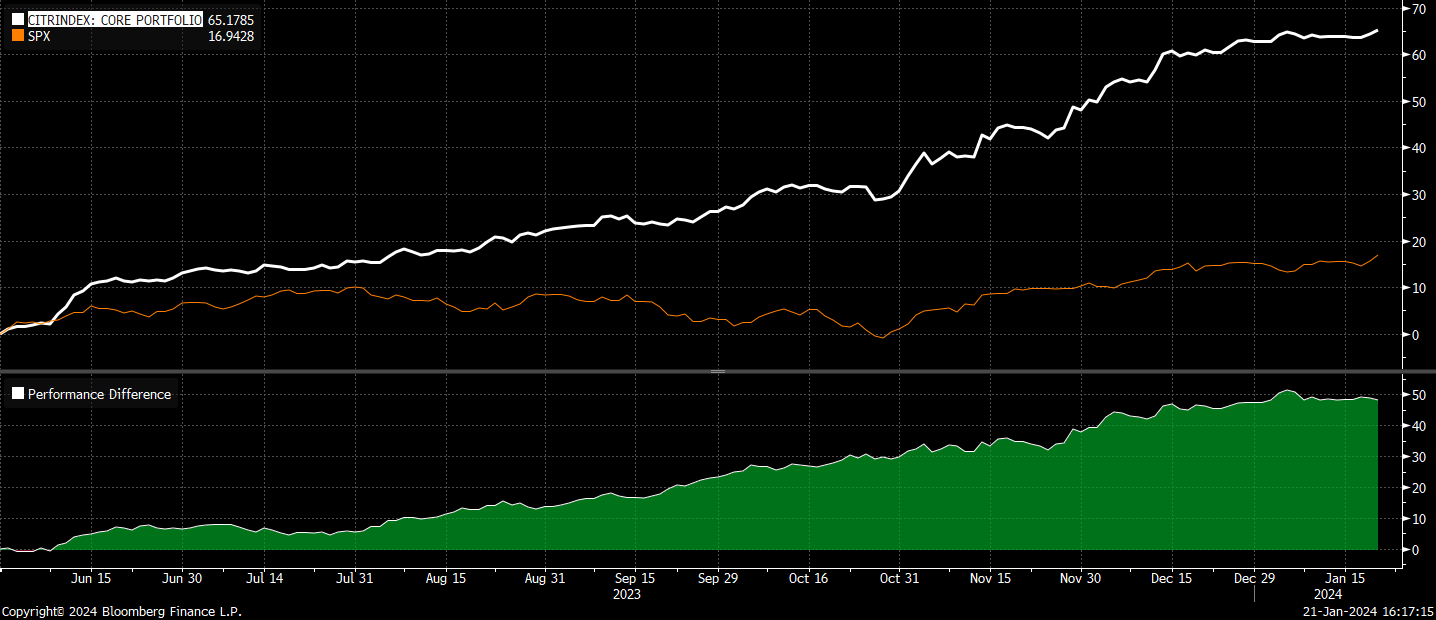
We’re up about 1.6% on the year (measuring from Jan 1 because we have international equity exposure) pretty much in line with the SPX:
HEDGING
In the .SPXHDG basket, which originally contained out February 4550 put hedges, I’ve broadened it out a bit. I think that we face the potential of a newly negative stock bond correlation that happens if equities go negative YTD (as retired boomers are severely over allocated to equities vs bonds, with many just in 100% equities, and the only way they’ll change that - in my opinion - is if the YTD number on their statement turns red). I’m going to begin using bond calls to hedge as well as equity index puts. This is also because higher rates and a reacceleration in inflation affect the cycle sensitive names we are exposed to less than a severe recession would.
So I added some 30 delta calls on 10 Year Treasury Futures (TY / ZN), to hedge our significant cyclical exposure against any economic weakness, and then rolled out those SPX hedges to March 28th 4800 puts.
As I’ve said before, BEWARE THE IDES OF MARCH (and the end of February).
Owning puts between Feb 19th and March 21st has saved my ass at least 3 times in the past 5 years. So I don’t care if it’s superstition, we’re buying puts!
I’ve added this hedge at a 200bps of NAV portfolio weight.
Updated Core Portfolio Holdings & Weights
Paid Subscribers Only
Paid subscribers can view the updated holdings by following the link on the Citrindex page here. Oh, and there are tickers now!
This will get an update when the election landscape is more clear, I don’t want to speculate needlessly.
SemiAnalysis has been a wealth of knowledge throughout the entire semi industry’s reaction to AI, you should definitely subscribe
Is there a way to buy SK hynix without going to S Korea?
Thank you for a thorough article.
What do you think of the current market pricing of Fed - I believe this can affect many of your plays here, if we see a repricing of the 5+ cuts currently priced in.
The next two CPIs, NFPs are (more then usual) high risk events for both the cuts priced in and stocks specially taking into account how US data has continued to surprise positive lately.
I see your hedges, just want to know what you think of this
Thanks!